
在日常生活工作中,我们难免会遇到一些问题,比如自己辛辛苦苦写完的资料,好不容易打印出来却发现源文件丢了;收集了一些名片,却要一个一个地录入信息,很麻烦。
那么,有没有什么技术能帮助我们解决这些难题呢?
有的,那就是OCR文字识别技术。

OCR英文全称是Optical Character Recognition,中文叫做光学字符识别。它是利用光学技术和计算机技术把印在或写在纸上的文字读取出来,并转换成一种计算机能够接受、人又可以理解的格式。
比如一个手机APP就能帮忙扫描名片、身份证,并识别出里面的信息;汽车进入停车场、收费站都不需要人工登记了,都是用车牌识别技术;我们看书时看到不懂的题,拿个手机一扫,APP就能在网上帮你找到这题的答案等等…这些都依赖于OCR技术得以实现。

OCR识别系统目的很简单,就是把影像作一个转换,使影像内的图形继续保存、有表格则表格内资料及影像内的文字,一律变成计算机文字,使能达到影像资料的储存量减少、识别出的文字可再使用及分析,这将大大节省因键盘输入的人力与时间,提高办公自动化程度,实现真正的端到端的业务流程自动化。
常见的OCR流程如下图所示:

其中影响识别准确率的技术瓶颈是文字检测和文本识别,而这两部分也是OCR技术的重中之重。
1.图像预处理
由于纸张的厚薄、光洁度和印刷质量都会造成文字畸变,产生断笔、粘连和污点等干扰,所以在进行文字识别之前,要对带有噪声的文字图像进行处理。
由于这种处理工作是在文字识别之前,所以被称为预处理,一般包括灰度化、二值化,倾斜检测与校正,行、字切分,平滑,规范化等等。
传统OCR基于数字图像处理和传统机器学习等方法对图像进行处理和特征提取。常用的二值化处理有利于增强简单场景的文本信息,但对于复杂背景二值化的收效甚微。
由于深度学习的飞速发展,现在普遍使用基于CNN的神经网络作为特征提取手段。得益于CNN强大的学习能力,配合大量的数据可以增强特征提取的鲁棒性,面临模糊、扭曲、畸变、复杂背景和光线不清等图像问题均可以表现良好的鲁棒性。
2.文字检测
CTPN(Connectionist Text Proposal Network)是目前应用最广的文本检测模型之一。
其基本假设是单个字符相较于异质化程度更高的文本行更容易被检测,因此先对单个字符进行类似R-CNN的检测。
之后又在检测网络中加入了双向LSTM,使检测结果形成序列提供了文本的上下文特征,便可以将多个字符进行合并得到文本行。
有一些研究引入了注意力机制,如下图模型采用Dense Attention模型来对图像的权重进行评估。这样有利于将前景图像和背景图像分离,对于文本内容较之背景图像有着更高的注意力,使检测结果更准确。
3.文本识别
视觉注意力模型(CNN+LSTM+Attention技术),该模型首先在图像上采用滑动窗口CNN(Convolutional Neural Network,卷积神经网络)的方法进行图像特征提取,然后在CNN的顶部堆叠一个LSTM(Long Short-Term Memory networks,长短期记忆网络)进行序列特征提取,最后,使用注意力模型作为解码器输出最终的文字序列。
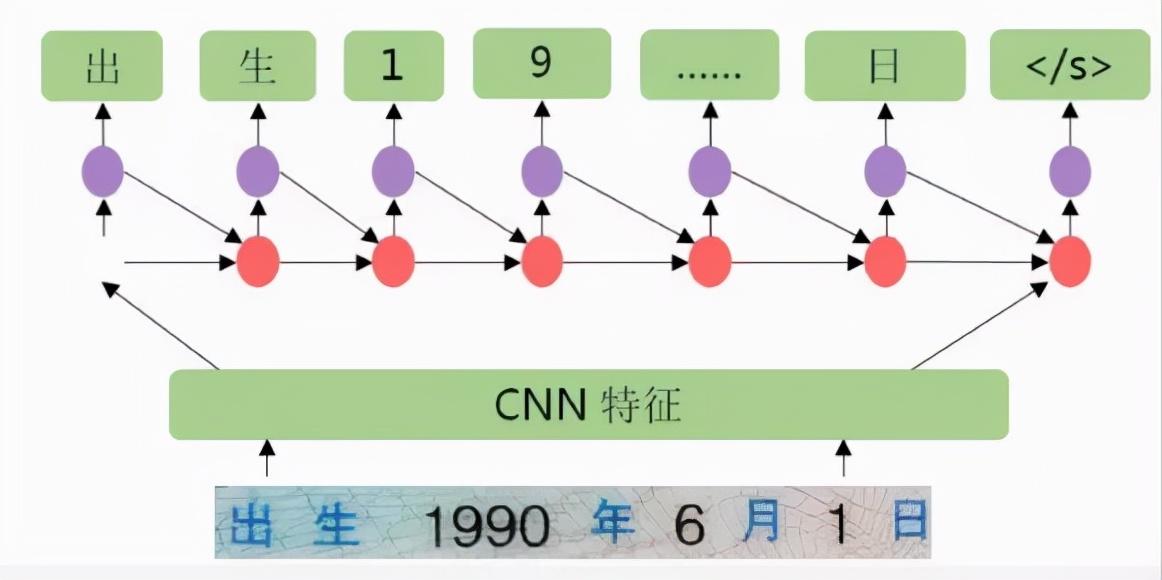
尽管基于深度学习的OCR表现相较于传统方法更为出色,但是深度学习技术仍需要在OCR领域进行特化,另一方面,作为深度学习的推动力,数据起到了至关重要的作用,因此收集广泛而优质的数据也是现阶段OCR性能的重要举措之一。
因为使用OCR技术,它快速高效的实现信息采集录入,不再需要浪费人力来进行录入登记、也不用花费众多的物力。它在节省时间成本,大幅度提高工作效率的同时,也颠覆了传统的工作模式,为社会各行各业向信息化迈进贡献力量。















